菜鸟笔记之PWN入门(1.1.2)C程序调用过程与函数栈变化(32位 vs 64位)(Intel)
本文使用Intel 的32位为例子进行举例。64位本质上和32位类似,主要区别在于函数参数的调用方式,文章结尾会简要提及。
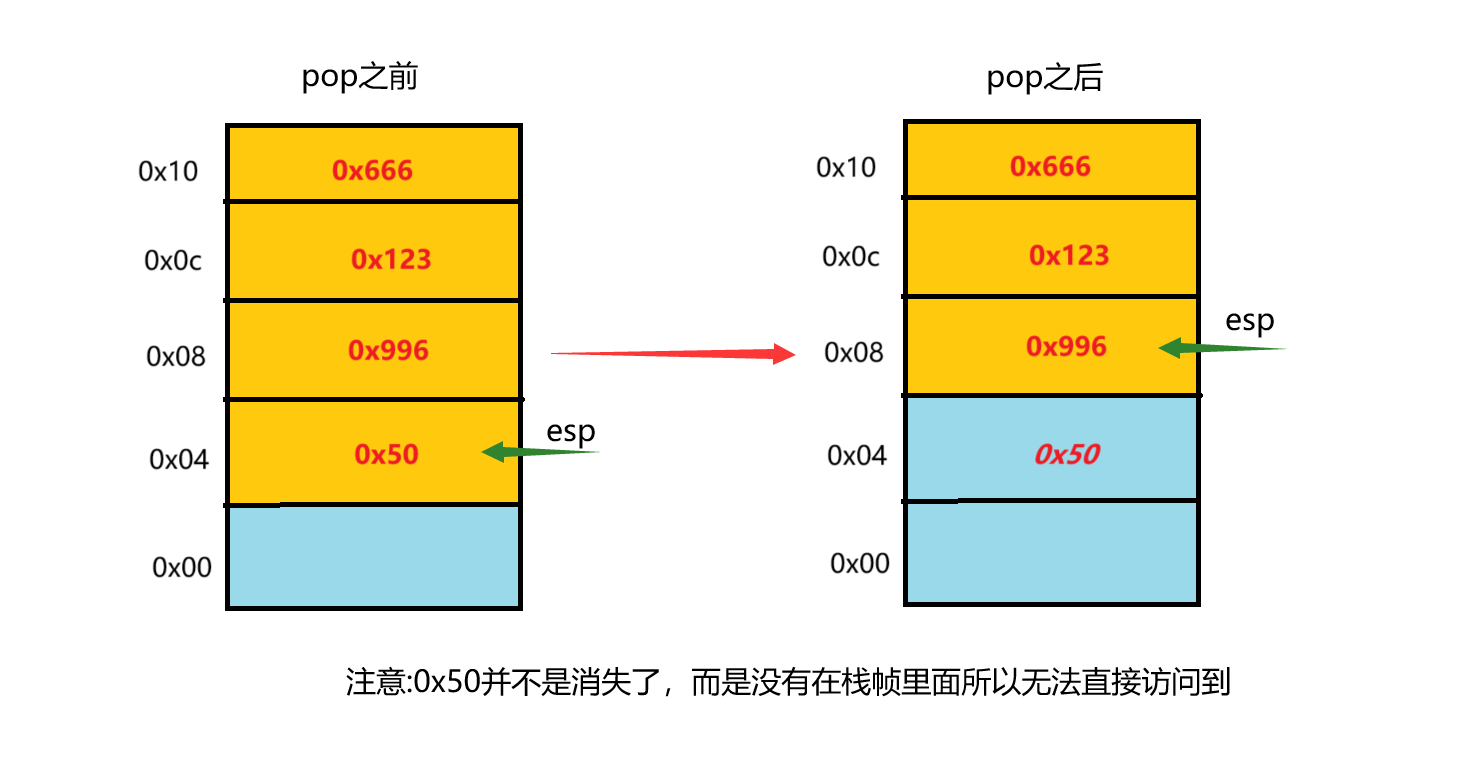
重新回顾一下栈pop和push指令
1 | |
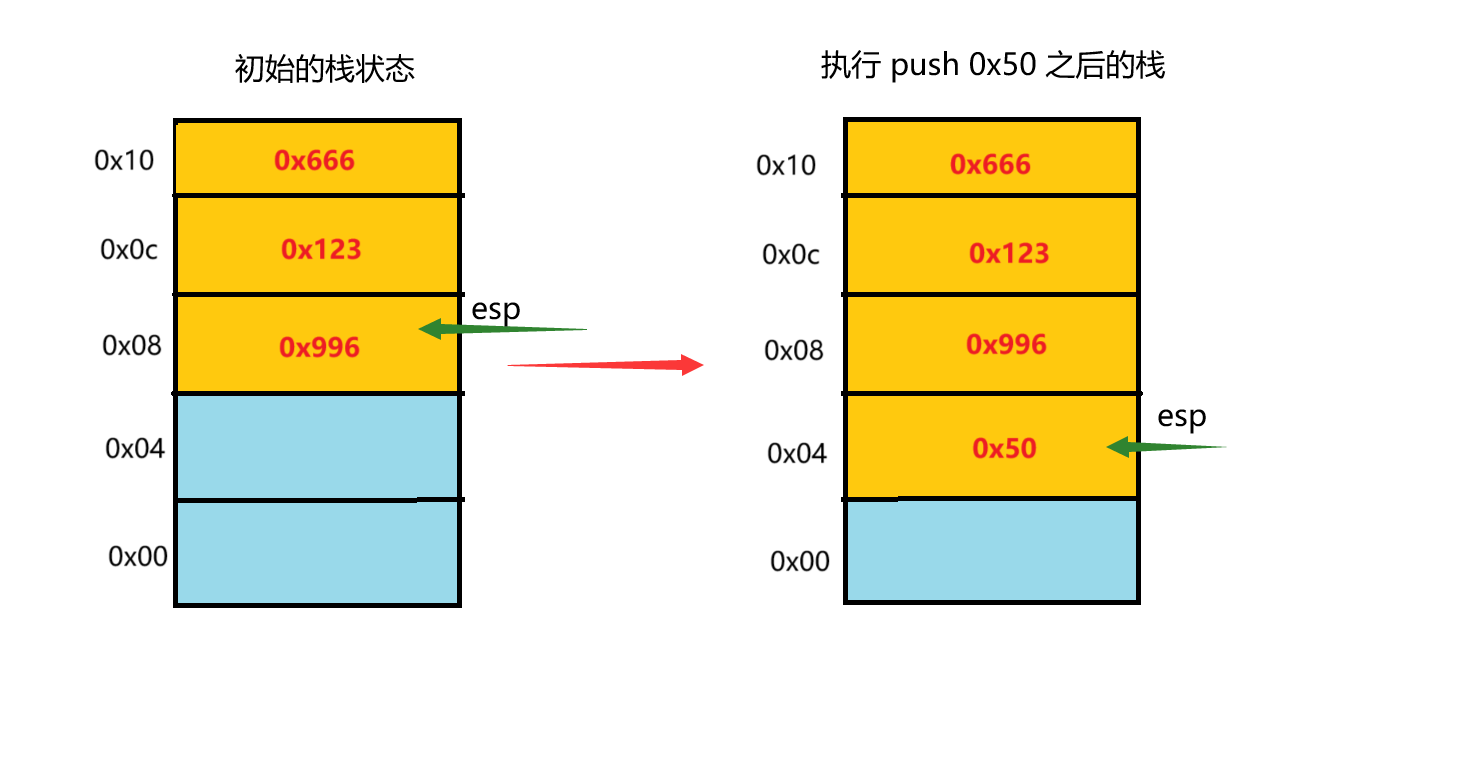
1 | |
栈帧是什么?
栈帧,也就是stack frame,其本质就是一种栈,只是这种栈专门用于保存函数调用过程中的各种信息(参数,返回地址,本地变量等)。栈帧有栈顶和栈底之分,其中栈顶的地址最低,栈底的地址最高,SP(栈指针)就是一直指向栈顶的。在x86-32bit中,我们用 ebp 指向栈底,也就是基址指针;用 esp 指向栈顶,也就是栈指针。下面是一个栈帧的示意图:
1 | |
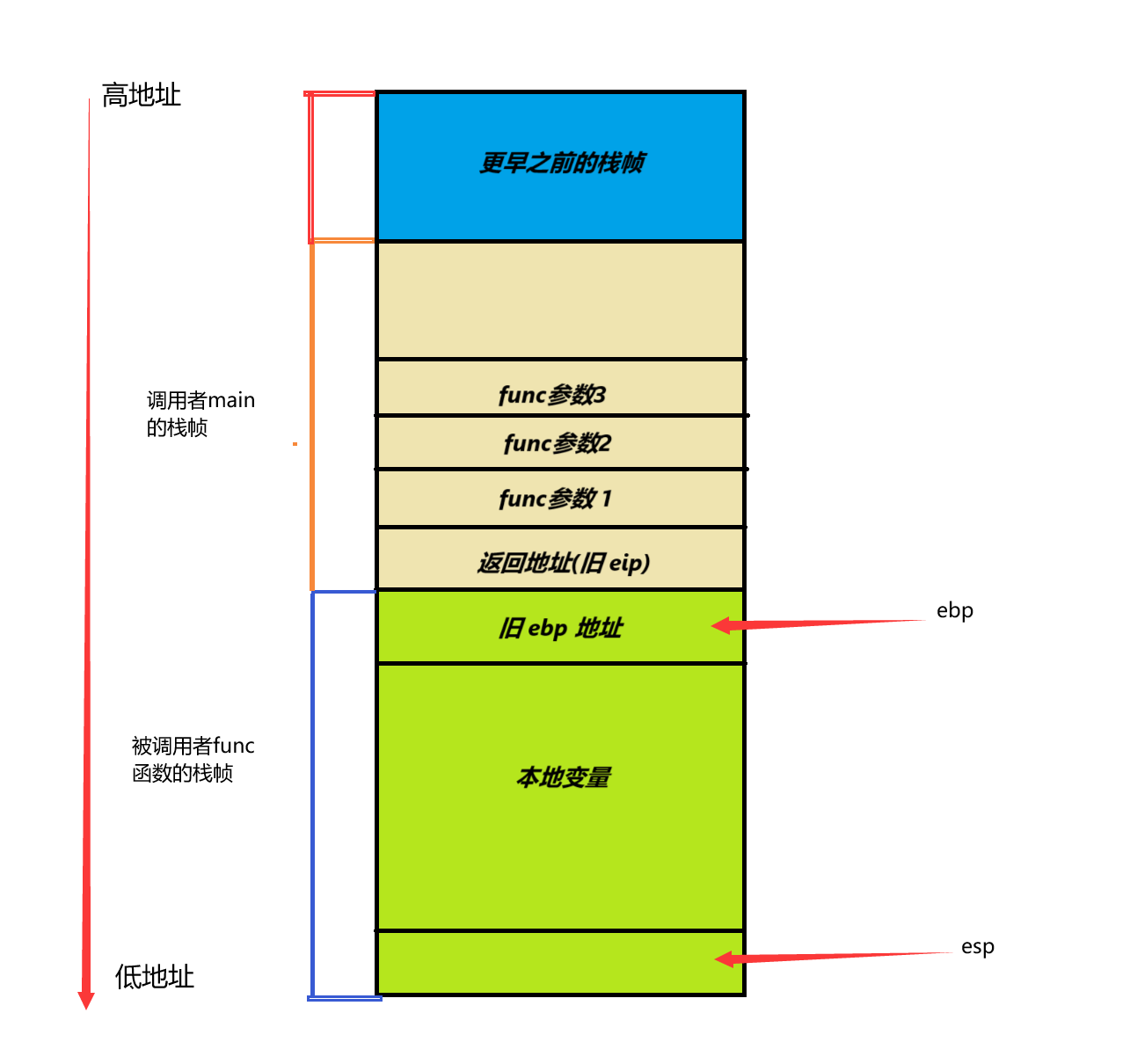
我们来详细分析一下上面的这个图和那一小段代码
1.其实main函数只是我们作为程序员认为的程序的入口,实际上在main函数之前编译器还会添加很多函数比如start函数等等,所以main函数的栈帧之前还是有栈帧的
2.最开始进入到main函数中,还没有执行func(参数1, 参数2 ,参数3 ) ;这条代码的时候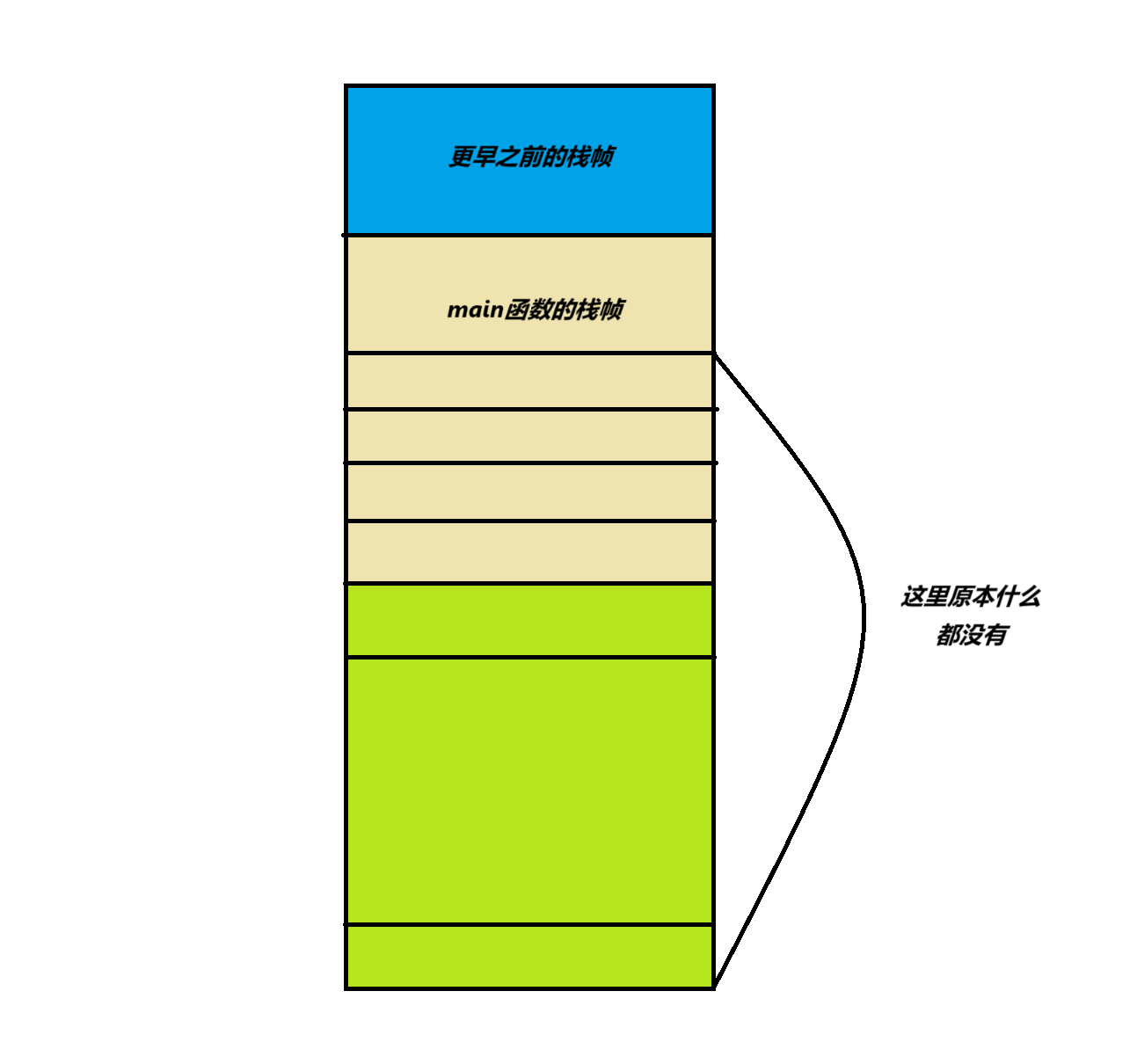
3.func(参数1, 参数2 ,参数3 ) ; 这一条语句在汇编语言中会被翻译成为call func
而在执行call func之前程序会执行一些push指令将func函数的参数1,2,3分别压入栈中
也就是push 参数3 push 参数2 push 参数1 这三条指令。执行完之后那么栈的内容会变成这样: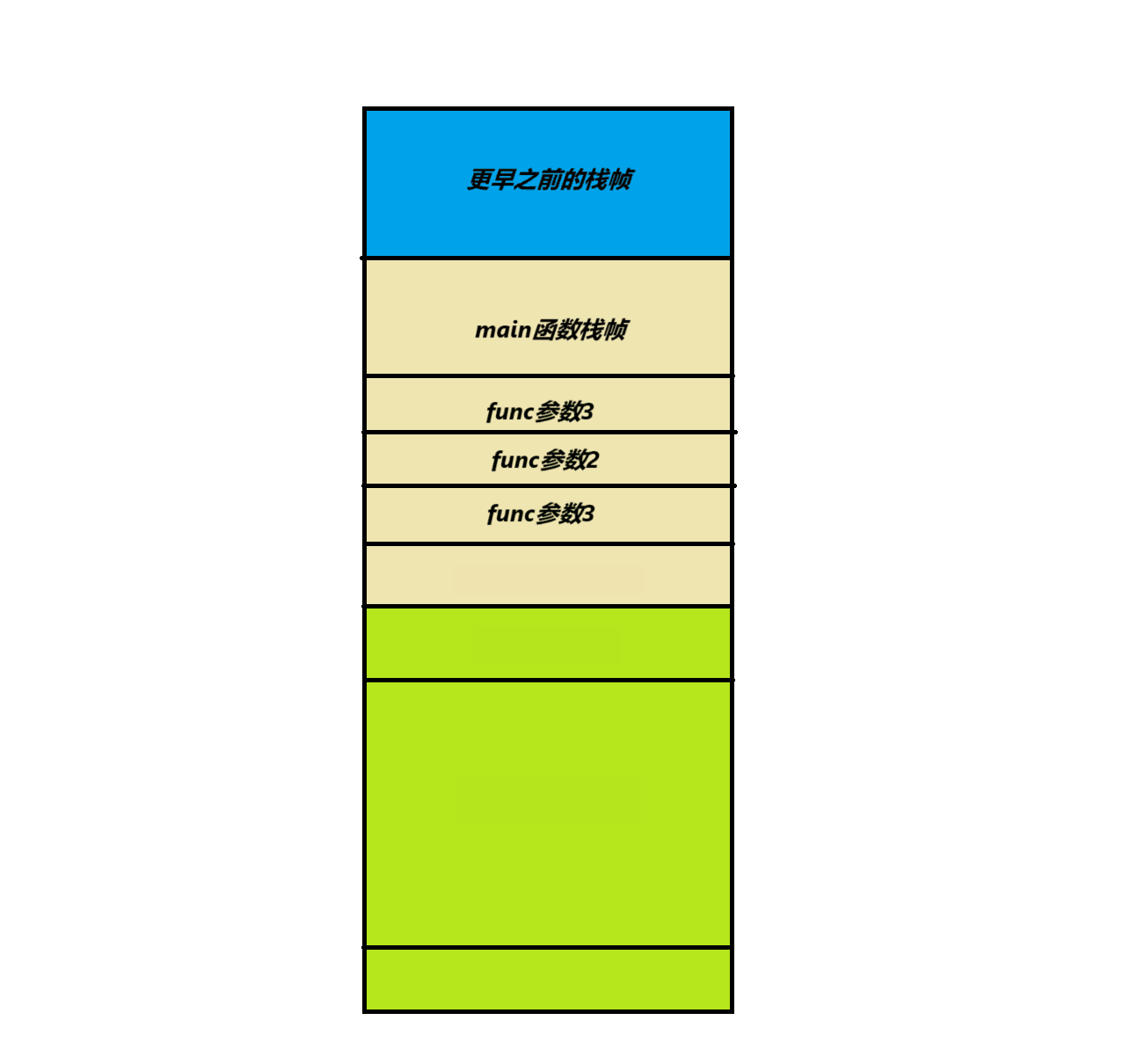
4.然后参数到位了就可以执行call func了。
而call func这个指令其实可以近似理解成push eip + jmp func_addr这两个指令的组合
如下图执行call func前后栈和eip指针的情况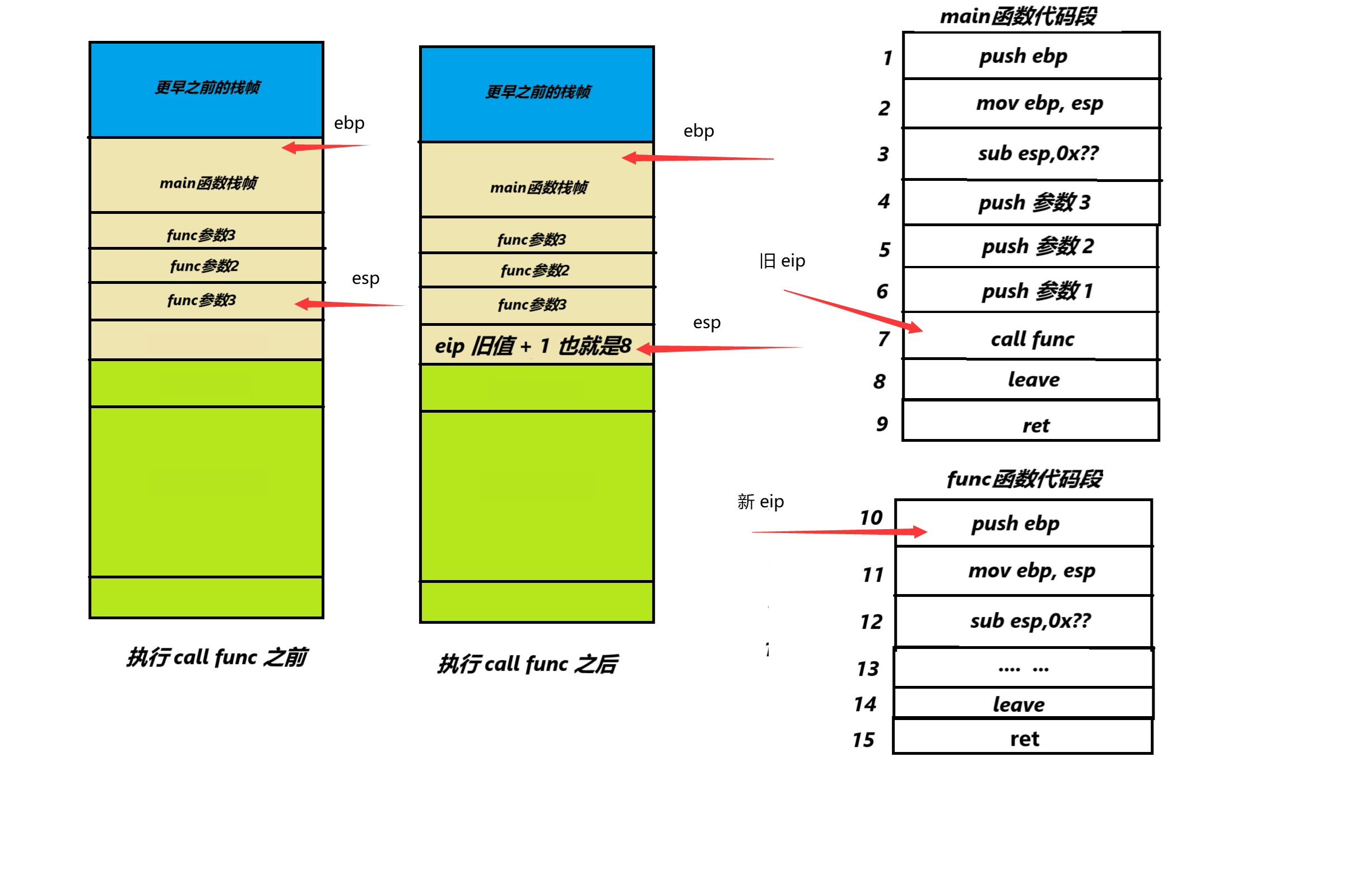
当然图中的代码段是我自己猜测的,不够准确,因为本文的目的是介绍函数调用的过程,所以没有考虑过多只是希望尽可能简单的将整个过程讲解清楚。
5.我们已经知道了执行call func之后的栈和eip的位置
然后我们介绍一下每个函数开头的初始化push ebp和mov ebp, esp
执行 push ebp 之后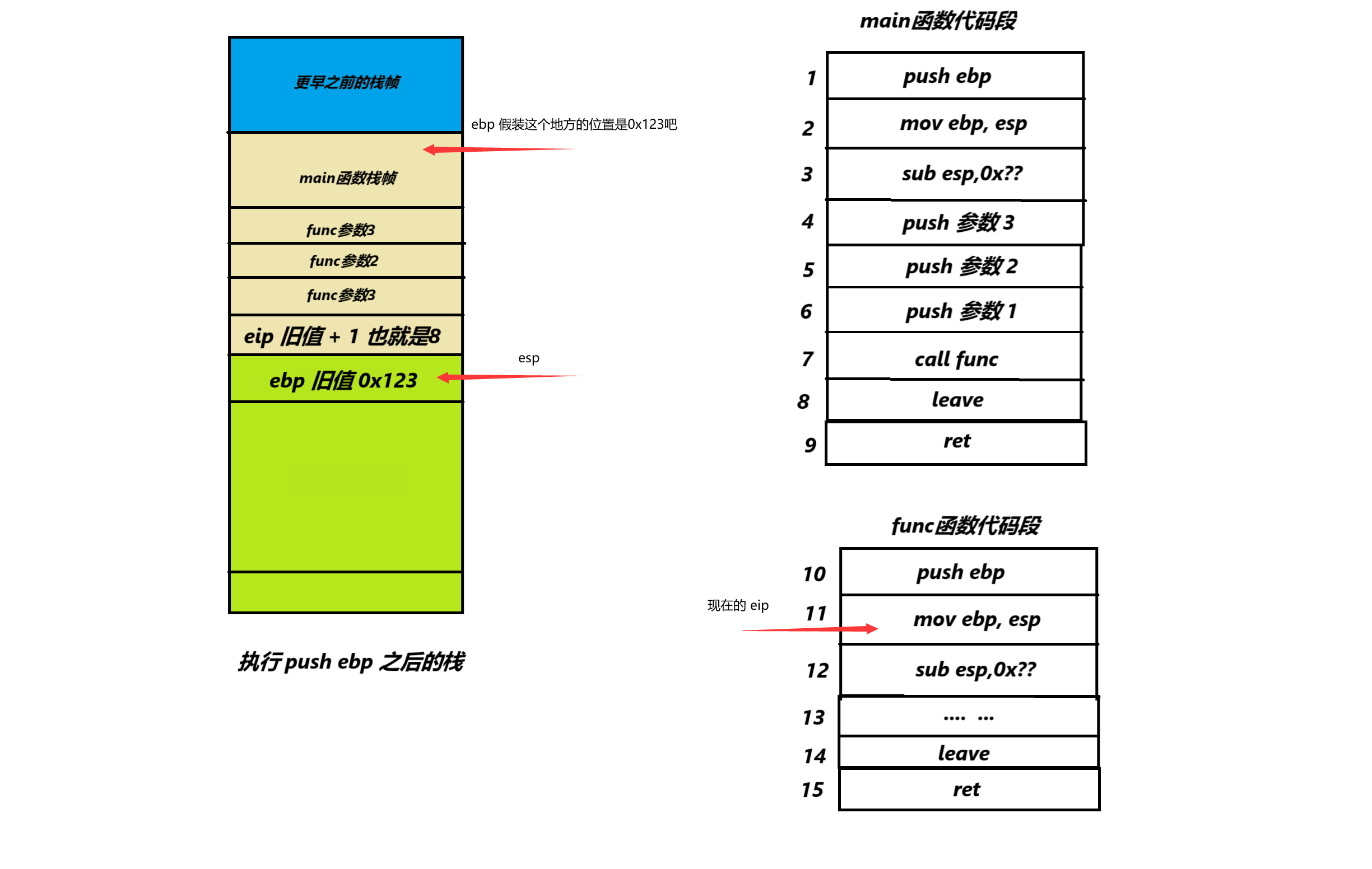
执行 mov ebp, esp 之后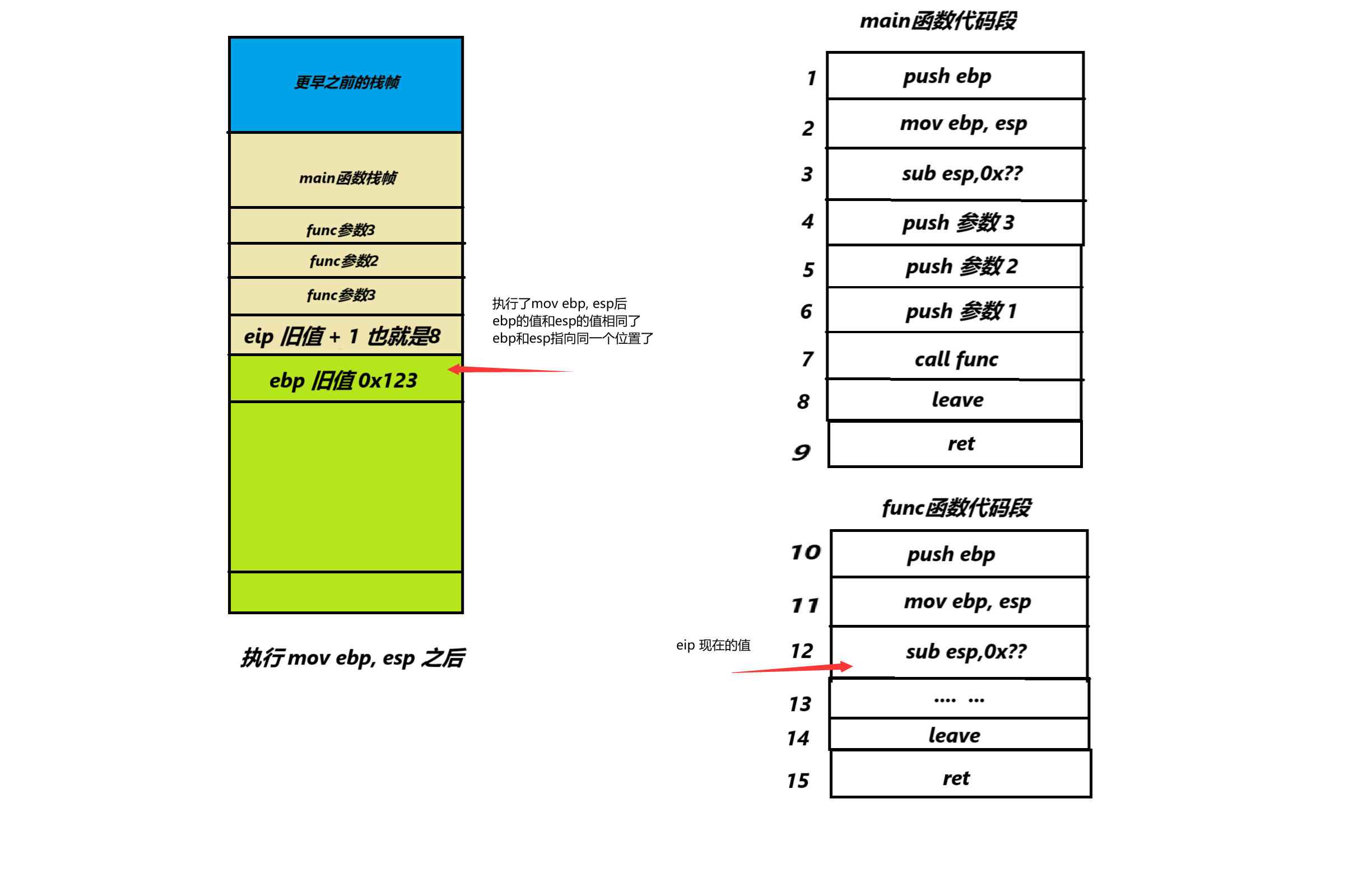
我们可以看到执行了mov ebp, esp之后ebp指针和esp指针指向了同一个地址,也就是ebp 旧值 所在的位置
6.在上一步中我们的esp和ebp处于同一个位置,然后我们需要执行sub esp, 0x??(这里打?是因为我不知道具体应该减去多少),这个sub指令在这里的作用是将esp向下移动,用于开出新函数所需要的栈帧,执行之后如下图: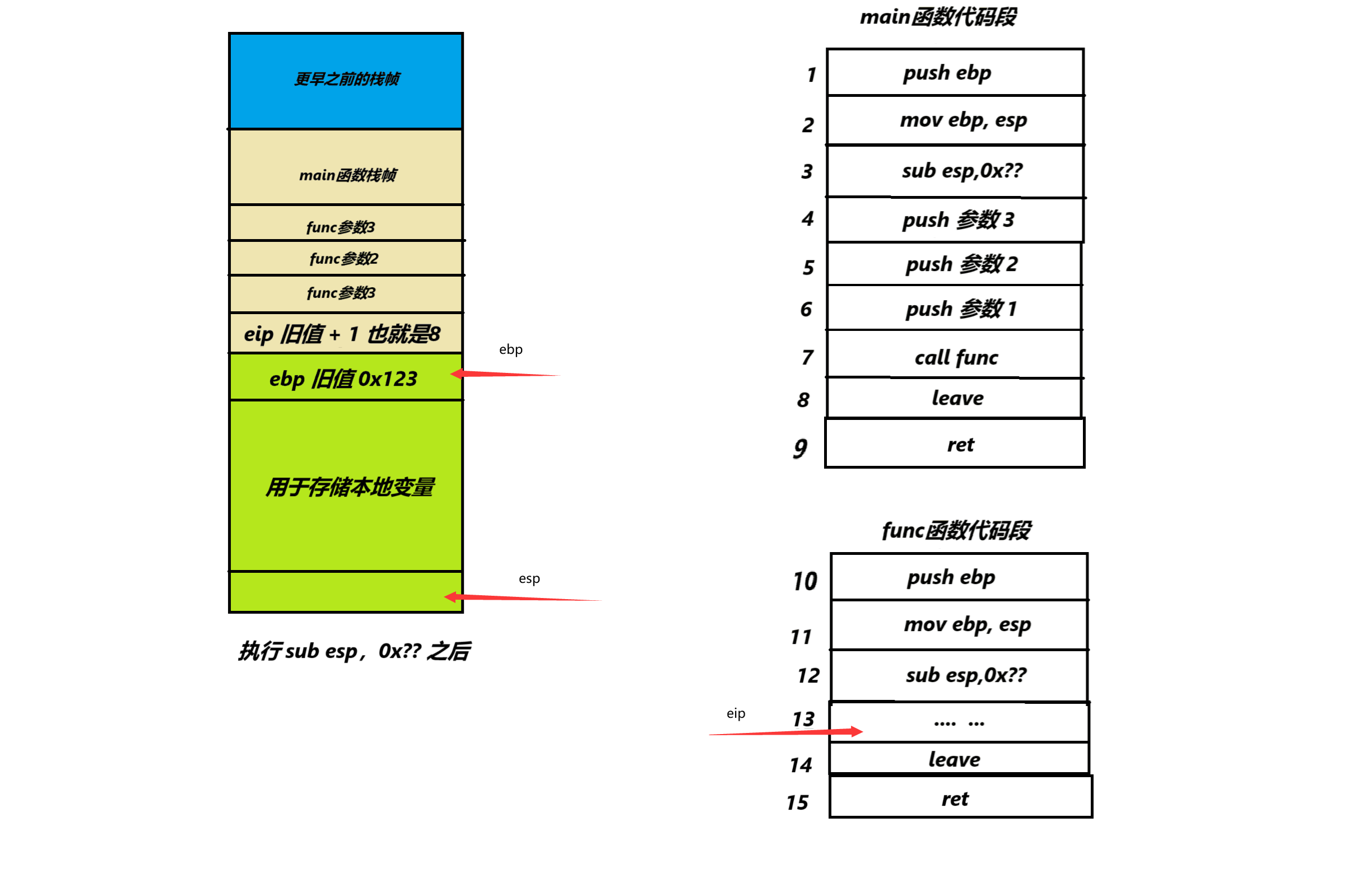
7.最后我们直接来看func函数的最后一条leave指令leave指令是mov esp,ebp和pop ebp的结合
我们来一条一条的看,先看 mov esp, ebp 执行之后的效果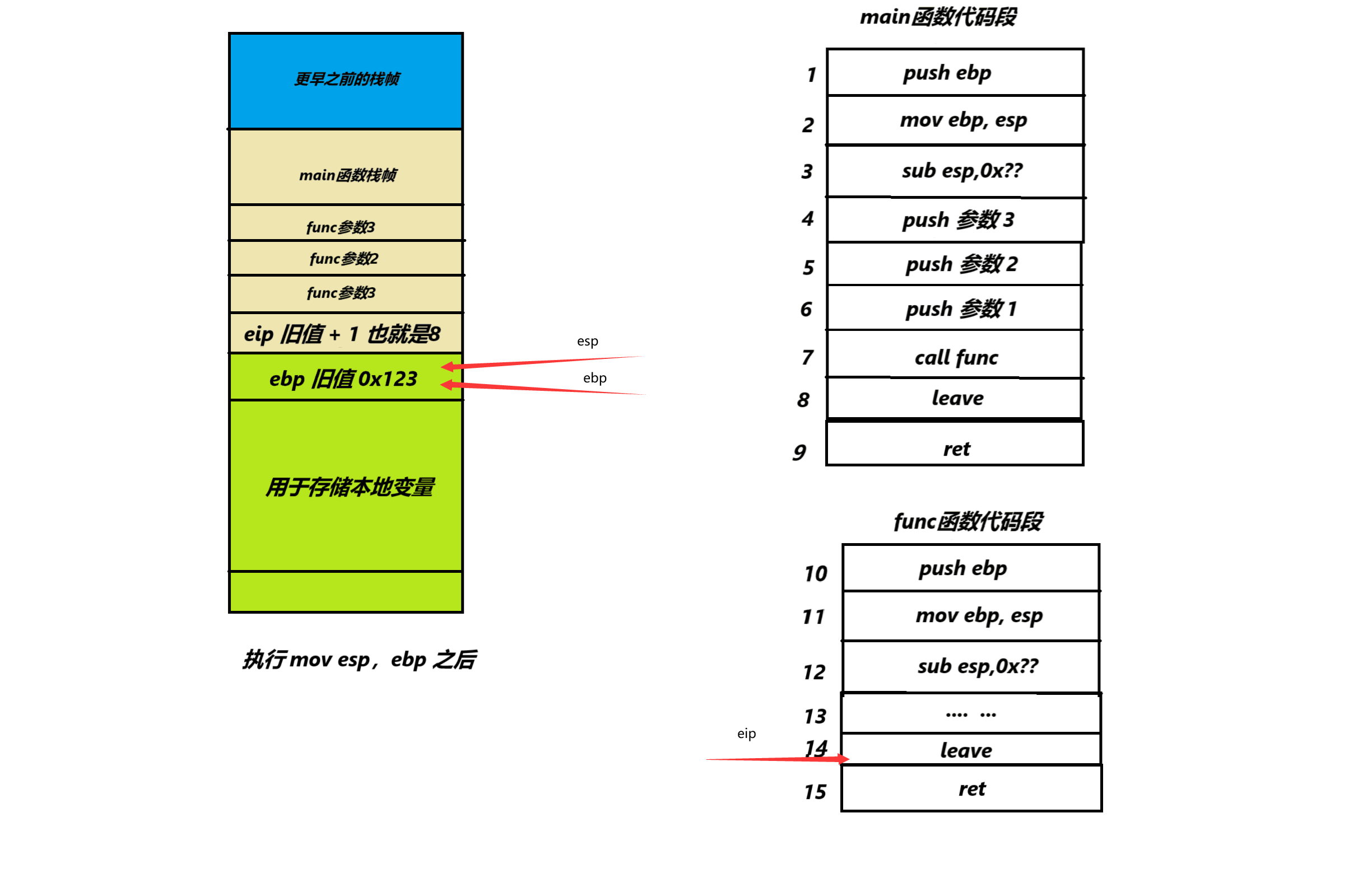
这条指令会重新将esp和ebp移动到同一个位置
然后再来看 pop ebp 执行之后的效果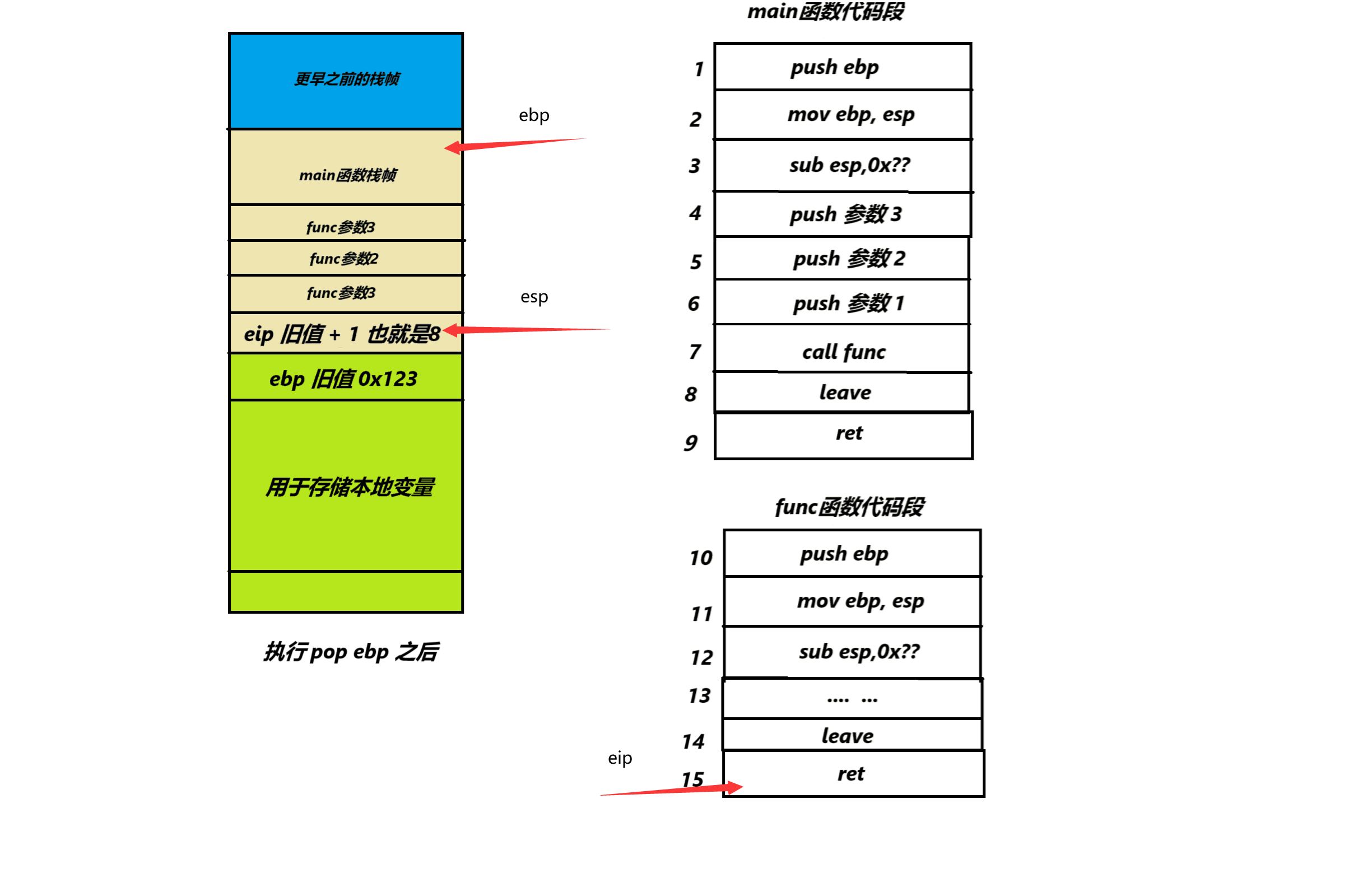
我们发现此时ebp回到最初在main函数中它的位置,而esp因为pop会向上移动一格位置,来到了eip旧地址储存的位置(这是后面会提到的栈溢出的关键部分)
8.紧接着我们就会执行ret指令,这个ret指令的作用相当于 pop eip 也就是将esp现在指向的值,赋值给eip,执行完这个语句之后,我们来看看eip在哪。如图: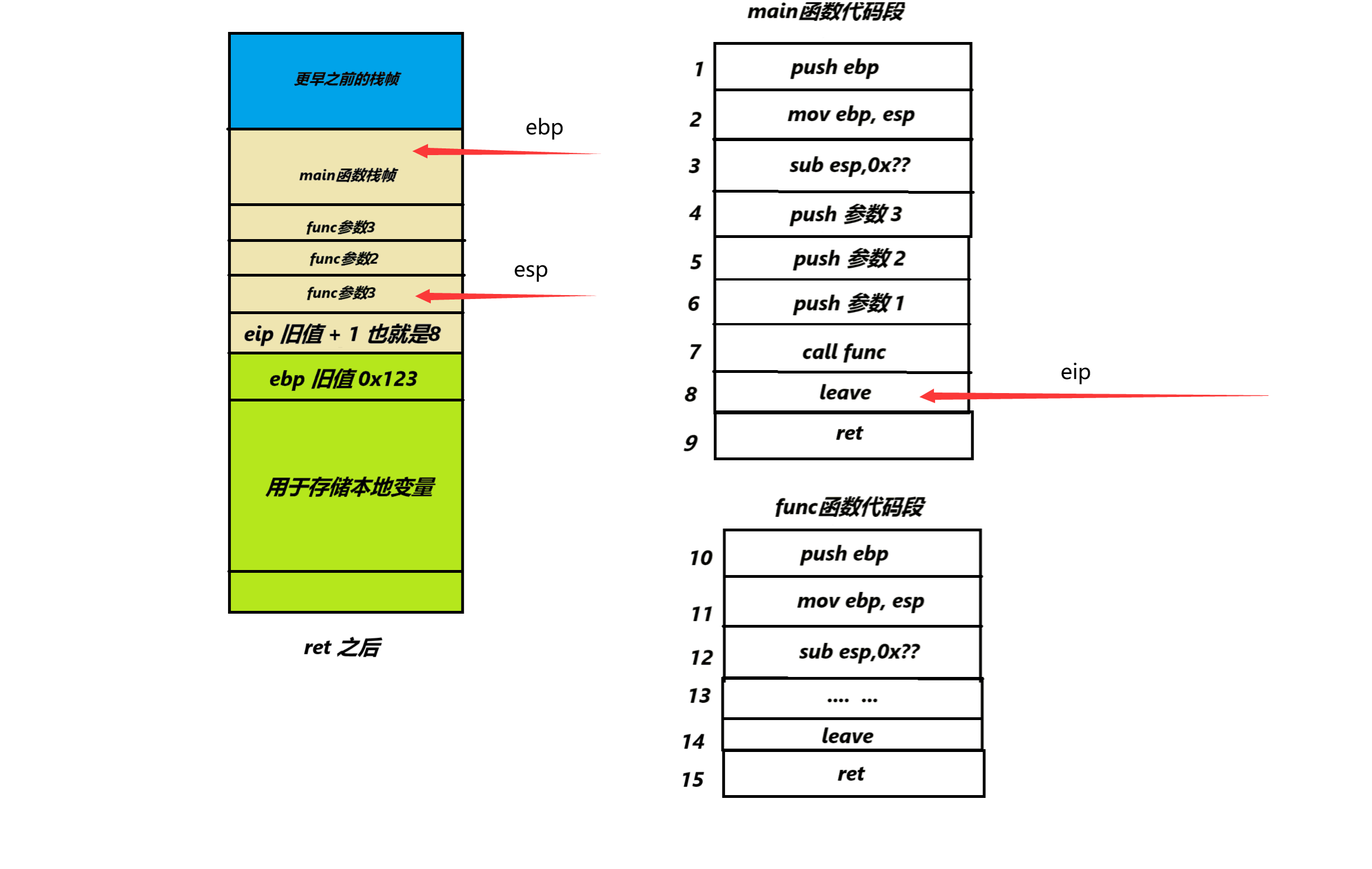
我们可以看到,栈一切都回到了call func 这个指令执行之前,只有eip的位置改变了,仿佛它从没来过…
到此为止32位程序函数的调用以及栈的变化就结束了,可以得到一个结论就是函数调用前后,栈内状况不变。其实这非常好理解,因为在一个函数中调用另外一个函数当然不能影响原函数的运行,所以栈的设计做到了用完就丢。被调用函数结束后esp和ebp的位置都会回到call这个指令之前的状态,而esp和ebp之间的数据也都没有改变
上述结论在64位中同样适用,而64位程序和32位程序除了位数上不同,最大的不同就在于64位程序会优先将被调用函数的参数存放在寄存器中
这是32位函数调用:
1 | |
而这是64位函数调用:
1 | |
在64位程序中,函数的参数会依次放入rdi rsi rdx rcx r8 r9 这六个寄存器中,只有把这六个寄存器塞满后,才会从右到左依次放入栈中,像上面的代码,func函数有8个参数,那么就如图所示: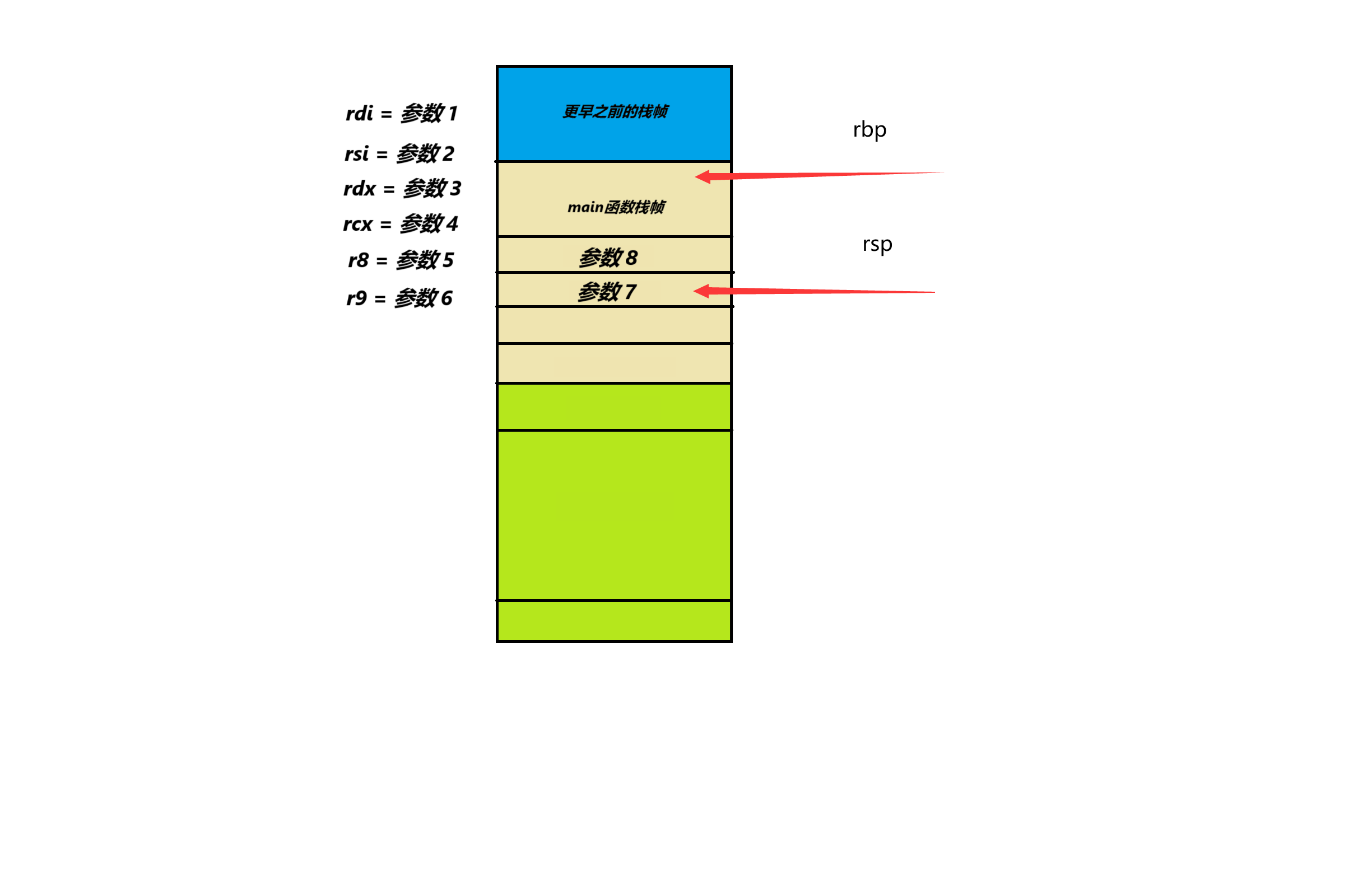
注意:64位所用的是位数更多更大的RSP和RBP
总结
其实程序本身的流程并不困难,只是初学者对汇编语言的了解较少所以难以理解,如果对于文章内容难以理解,不妨寻找一些汇编语言的教程较为系统的了解汇编语言也许会有所帮助
(制作图片用的是win11自带的画图工具,里面的字体大小不知道为什么调节不了,所以出现了字体很小的情况,(。・_・。)ノI’m sorry~)
参考文献:
PWN入门(1-1-1)-C函数调用过程原理及函数栈帧分析(Intel) (yuque.com)
linux - C函数调用过程原理及函数栈帧分析 - 编程之道 - SegmentFault 思否