菜鸟笔记之PWN入门(1.1.3)Linux基础操作和ELF文件保护
这里不讨论Linux的历史及其与Windows的比较。直接介绍一些简单基础的操作。
首先我们需要安装一个Linux操作系统(首先推荐Ubuntu),我们需要安装一个VM虚拟机,然后在里面搭建一个Ubuntu的虚拟机
可以直接百度搜索,这里推荐一个文章
安装虚拟机(VMware)保姆级教程(附安装包)_vmware虚拟机-CSDN博客
根据教程你可以成功安装Ubuntu虚拟机之后
第一件事情不是配置PWN环境,而是更换源
Ubuntu 更换国内源_ubuntu换源-CSDN博客
然后按照顺序安装GCC --> python3 --> VMtools
然后进行PWN虚拟机的安装:
https://hollk.blog.csdn.net/article/details/118188924?spm=1001.2014.3001.5502
PWN的大部分工具需要从github上下载,请确保你的网络能够顺利连接github,建议科学上网,否则下载成功与否只能看运气…
当然,如果你感觉很麻烦,我已经安装好了一个Ubuntu22的虚拟机,下面提供百度网盘链接:
通过网盘分享的文件:VM22XiDP_ovf
链接: https://pan.baidu.com/s/1NYJ7NywYab6LUC_kZgRxPQ?pwd=xidp
提取码: xidp
虚拟机密码:用户xidp :密码 xidpxidp..用户root :密码 xidpxidp..
虚拟机可能存在bug,可以在github上向我留言,如果有需要添加的工具也可以留言:XiDP0/Pwn-Ubuntu22 (github.com)
查看当前目录:
pwd:打印当前工作目录路径。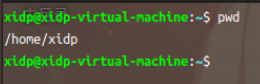
列出目录内容:
ls:列出当前目录的文件和文件夹。ls -l:显示详细信息。ls -a:显示所有文件,包括隐藏文件。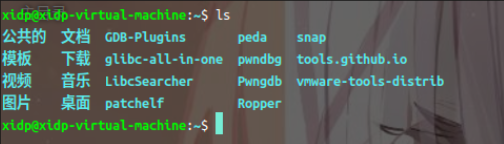
切换目录:
cd 目录名:进入指定目录。cd ..:返回上级目录。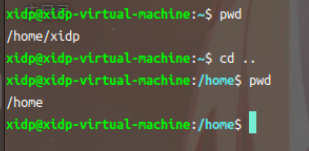
创建文件和目录:
touch 文件名:创建空文件。mkdir 目录名:创建新目录。
删除文件和目录:
rm 文件名:删除文件。rm -r 目录名:递归删除目录及其内容。
移动和重命名文件:
mv 源文件 目标:移动或重命名文件或目录。
复制文件和目录:
cp 源文件 目标:复制文件。cp -r 源目录 目标:递归复制目录。
查看文件内容:
cat 文件名:显示文件内容。less 文件名:分页查看文件内容,适合查看长文件。
编辑文件:
nano 文件名或vim 文件名:使用nano或vim编辑文件。
查找文件:
find /路径 -name 文件名:在指定路径下查找文件。
显示系统信息:
uname -a:显示系统信息。top:查看当前运行的进程和系统资源使用情况。
查看和管理进程:
ps aux:列出所有进程。kill 进程ID:终止指定进程。
清空当前页面:
clear
获取管理员权限:
第一次登入的时候你会发现你没有设置root权限
sudo +命令:以超级用户权限执行命令。sudo允许普通用户临时获取管理员权限来执行特定任务。sudo root:输入密码后成为高级用户(输入的密码是看不见的)。
输入文本内容:
cat:显示文件内容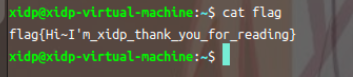
(为什么只放四个图? 因为我懒…)
接下来重点讲解ELF文件的保护有哪些:
ELF文件保护
Linux ELF文件的保护主要有四种:
Canary
NX
PIE
RELRO
分别用于应付不同的漏洞,同时后面我们也会学习绕过它们的方法,下面让我们来分别了解它们的工作原理和起到的保护作用
1.Canary
Canary是金丝雀的意思。技术上表示最先的测试的意思。
这个来自以前挖煤的时候,矿工都会先把金丝雀放进矿洞,或者挖煤的时候一直带着金丝雀。金丝雀对甲烷和一氧化碳浓度比较敏感,会先报警。所以大家都用Canary来搞最先的测试。
Linux的Canary指的是在ebp/rbp旧值之前添加的一串随机数(不超过机械字长)(也叫做cookie),当程序会在执行到此处的时候会检测Canary的值是否和刚开始的一样,如果出现缓冲区溢出攻击,覆盖到了Canary(也就是Canary的值发生了改变),系统检测到Canary的值发生了变化,那么程序会立马崩溃,以防止被篡改的程序执行奇怪的东西
而Canary的末位一定是\x00。\x00是一个用于表示字符串结束的符号,也就是说类似puts函数这类函数输出字符串的时候遇到\x00就会停止继续输出(同样strcpy函数复制字符串的时候遇到\x00也会停止,后面会讲到这个\x00也有不同的用法可以绕过一些检测)。
之所以Canary的末位添加\x00是因为计算机往往是小端程序。比如:Canary是0x1122334455667700。
那么在计算机中储存的时候它是:\x00\x77\x66\x55\x44\x33\x22\x11这样储存的
那么\x00就在内存的开头了,当Canary前面有字符串需要输出的时候,一直到Canary的\x00就会停下。这使得Canary不会被输出,以此保护Canary不泄露(之后我们会讲到一种绕过Canary的方法就是尝试覆盖掉这个\x00让Canary被puts之类的函数输出)
GCC开启Canary和关闭Canary
1 | |
Canary所在的位置和GCC编译器以及系统有关:
下面以Ubuntu系统举例: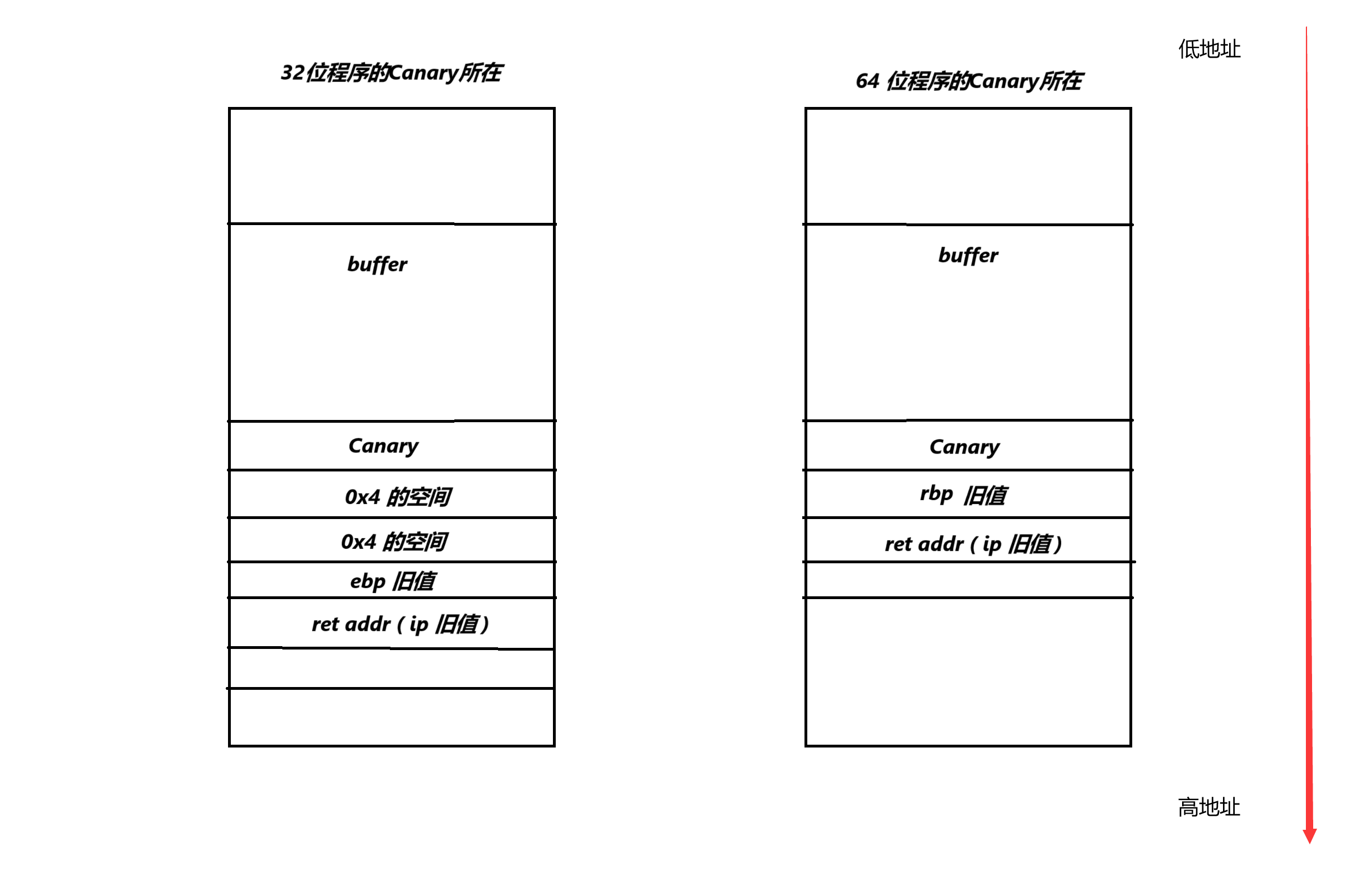
注意:前面的文章中我制作的图片都是使用上面为高地址,下面为低地址(因为初学者都相对自然的认为上高下低),但是此处我采用了上低下高。因为在后续我们做PWN题目的时候使用gdb调试,在gdb中查看栈,栈中的内容是上低下高的,图中所看到的情况也符合我们即将在gdb中看到的情况。所以为了让大家能够适应后续的gdb调试这里使用了上低下高,
所以总的来说,对于Ubuntu来说,32为程序的Canary一般在 ebp - 0xc 的地方(32位的一格是0x4,也就是在ebp的上面3格)。而 64位的Canary则是在 rbp - 0x8 的位置(64位的一格是0x8,也就是在ebp的上面1格,他们相邻)
2.NX保护
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行。
这个保护有什么用呢?
我们都知道程序分为代码段和数据段,代码段用于执行,数据段用于存储数据,那么我们可以在数据段写入一些代码吗?答案是可以的,但是程序执行什么由ip指针说了算,ip指哪就运行什么。那如果我们在数据段写入我们想要的代码,然后再想个办法把ip指针骗过来了呢?
这样就像银行卡里的数字自己可以改一样,非常逆天(后续我们会学到,这种逆天的攻击方法叫ret2shellcode,但是开启NX之后几乎就无效了)。
所以有了NX保护,它的任务就是让数据段坚决不能执行(在Ubuntu20版本之后,系统默认了数据段就是无法执行的,哪怕没有开启NX也不能执行数据段里面的东西)
GCC开启和关闭NX保护:
1 | |
3.PIE与ASLR
从我个人认为PIE与ASLR是非常麻烦的保护,它们的作用是让地址空间分布随机化
ASLR(libc地址随机化)ASLR(Address Space Layout Randomization)是一种操作系统级别的安全保护机制,旨在增加软件系统的安全性。它通过随机化程序在内存中的布局,使得攻击者难以准确地确定关键代码和数据的位置,从而增加了利用软件漏洞进行攻击的难度。 开启不同等级会有不同的效果:
内存布局随机化: ASLR的主要目标是随机化程序的内存布局。在传统的内存布局中,不同的库和模块通常会在固定的内存位置上加载,攻击者可以利用这种可预测性来定位和利用漏洞。 ASLR通过随机化这些模块的加载地址,使得攻击者无法准确地确定内存中的关键数据结构和 代码的位置。地址空间范围的随机化: ASLR还会随机化进程的地址空间范围。在传统的地址空间中,栈、 堆、代码段和数据段通常会被分配到固定的地址范围中。ASLR会随机选择地址空间的起始位置和大小,从而使得这些重要的内存区域在每次运行时都有不同的位置。随机偏移量: ASLR会引入随机偏移量,将程序和模块在内存中的相对位置随机化。这意味着每个模块的实际地址是相对于一个随机基址偏移的,而不是绝对地址。攻击者需要在运行时发现这些偏移量,才能准确地定位和利用漏洞。堆和栈随机化: ASLR也会对堆和栈进行随机化。堆随机化会在每次分配内存时选择不同的起 始地址,使得攻击者无法准确地预测堆上对象的位置。栈随机化会随机选择栈帧的起始位置, 使得攻击者无法轻易地覆盖返回地址或控制程序流程。
和PIE不同,PIE用于随机化代码段和数据段,ASLR用于将libc库以及堆栈的地址随机化。而ASLR是Linux系统本身提供的保护机制。
Linux下的ASLR分为三个级别,0,1,2
1 | |
1 | |
PIE
PIE能够使得程序像共享库一样在主存的任何位置装载,在需要将程序编译成位置无关
开放后code与data会随着ASLR变化地址IDA以及gdb执行的时候就只能看到地址后面的末尾三位数
GCC开启和关闭PIE
1 | |
4.RELRO
Relocation Read-Only (RELRO) 可以使程序某些部分成为只读的。
它分为两种:Partial RELRO 和 Full RELRO,即:部分RELRO 和 完全RELRO。
部分RELRO 是 GCC 的默认设置,几乎所有的二进制文件都至少使用部分RELRO。这样仅仅只能防止全局变量上的缓冲区溢出从而覆盖 GOT。
完全RELRO 使整个 GOT 只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动之前需要解析所有的符号。
在Linux系统安全领域数据可以写的存储区就会是攻击的目标,尤其是存储函数指针的区域。所以在安全防护的角度应尽量减少可写的存储区域
RELRO会设置符号重定向表格为只读或者程序启动时就解析并绑定所有动态符号,从而减少对GOT表的攻击。如果RELRO为Partial RELRO,就说明对GOT表具有写权限
具体GOT和PLT表是什么,有什么用,将在ret2libc的前置章节中讲解
主要用来保护重定位表段对应数据区域,默认可写
Partial RELRO:.got不可写,got.plt可写Full RELRO:.got和got.plt不可写
got.plt可以简称为got表
GCC开启和关闭RELRO
1 | |
5.fortify
fortify是轻微的检查,用于检查是否存在缓冲区溢出的错误。适用于程序采用大量的字符串或者内存操作函数,如:
1 | |
GCC开启和关闭fortify:
1 | |
在-D_FORTIFY_SOURCE=2时,通过对数组大小来判断替换strcpy、memcpy、memset等函数名,从而达到防止缓冲区溢出的作用
(最后这段直接复制了hollk师傅的博客内容)
到此我们讲完了ELF文件的常见保护。后续我们将从ret2backdoor开始讲解最最基础的PWN
参考文献:
栈保护机制-CSDN博客
linux elf保护机制_-no-pie-CSDN博客
Pwn的常见保护介绍_pwn题打开nx保护有什么用吗-CSDN博客
PWN入门(1-1-3)-Linux ELF文件保护机制 (yuque.com)